PROFESSIONAL-MACHINE-LEARNING-ENGINEER Online Practice Questions and Answers
You are developing ML models with AI Platform for image segmentation on CT scans. You frequently update your model architectures based on the newest available research papers, and have to rerun training on the same dataset to benchmark their performance. You want to minimize computation costs and manual intervention while having version control for your code. What should you do?
A. Use Cloud Functions to identify changes to your code in Cloud Storage and trigger a retraining job.
B. Use the gcloud command-line tool to submit training jobs on AI Platform when you update your code.
C. Use Cloud Build linked with Cloud Source Repositories to trigger retraining when new code is pushed to the repository.
D. Create an automated workflow in Cloud Composer that runs daily and looks for changes in code in Cloud Storage using a sensor.
You are designing an architecture with a serverless ML system to enrich customer support tickets with informative metadata before they are routed to a support agent. You need a set of models to predict ticket priority, predict ticket resolution time, and perform sentiment analysis to help agents make strategic decisions when they process support requests. Tickets are not expected to have any domain-specific terms or jargon.
The proposed architecture has the following flow:
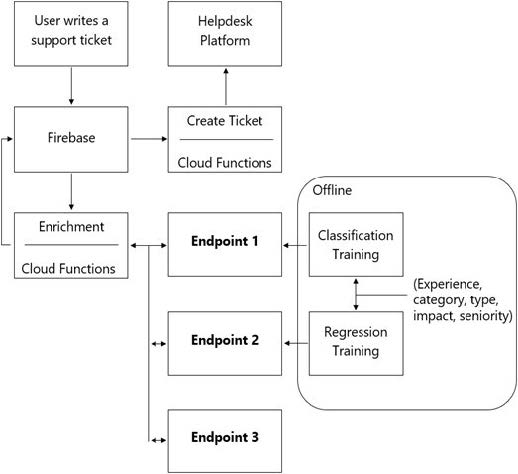
Which endpoints should the Enrichment Cloud Functions call?
A. 1 = AI Platform, 2 = AI Platform, 3 = AutoML Vision
B. 1 = AI Platform, 2 = AI Platform, 3 = AutoML Natural Language
C. 1 = AI Platform, 2 = AI Platform, 3 = Cloud Natural Language API
D. 1 = Cloud Natural Language API, 2 = AI Platform, 3 = Cloud Vision API
You are an ML engineer at a regulated insurance company. You are asked to develop an insurance approval model that accepts or rejects insurance applications from potential customers. What factors should you consider before building the model?
A. Redaction, reproducibility, and explainability
B. Traceability, reproducibility, and explainability
C. Federated learning, reproducibility, and explainability D. Differential privacy, federated learning, and explainability
You are training a TensorFlow model on a structured dataset with 100 billion records stored in several CSV files. You need to improve the input/output execution performance. What should you do?
A. Load the data into BigQuery, and read the data from BigQuery.
B. Load the data into Cloud Bigtable, and read the data from Bigtable.
C. Convert the CSV files into shards of TFRecords, and store the data in Cloud Storage.
D. Convert the CSV files into shards of TFRecords, and store the data in the Hadoop Distributed File System (HDFS).
You work on the data science team for a multinational beverage company. You need to develop an ML model to predict the company's profitability for a new line of naturally flavored bottled waters in different locations. You are provided with historical data that includes product types, product sales volumes, expenses, and profits for all regions. What should you use as the input and output for your model?
A. Use latitude, longitude, and product type as features. Use profit as model output.
B. Use latitude, longitude, and product type as features. Use revenue and expenses as model outputs.
C. Use product type and the feature cross of latitude with longitude, followed by binning, as features. Use profit as model output.
D. Use product type and the feature cross of latitude with longitude, followed by binning, as features. Use revenue and expenses as model outputs.
While running a model training pipeline on Vertex Al, you discover that the evaluation step is failing because of an out-of-memory error. You are currently using TensorFlow Model Analysis (TFMA) with a standard Evaluator TensorFlow Extended (TFX) pipeline component for the evaluation step. You want to stabilize the pipeline without downgrading the evaluation quality while minimizing infrastructure overhead. What should you do?
A. Include the flag -runner=DataflowRunner in beam_pipeline_args to run the evaluation step on Dataflow.
B. Move the evaluation step out of your pipeline and run it on custom Compute Engine VMs with sufficient memory.
C. Migrate your pipeline to Kubeflow hosted on Google Kubernetes Engine, and specify the appropriate node parameters for the evaluation step.
D. Add tfma.MetricsSpec () to limit the number of metrics in the evaluation step.
You are analyzing customer data for a healthcare organization that is stored in Cloud Storage. The data contains personally identifiable information (PII). You need to perform data exploration and preprocessing while ensuring the security and privacy of sensitive fields. What should you do?
A. Use the Cloud Data Loss Prevention (DLP) API to de-identify the PII before performing data exploration and preprocessing.
B. Use customer-managed encryption keys (CMEK) to encrypt the PII data at rest, and decrypt the PII data during data exploration and preprocessing.
C. Use a VM inside a VPC Service Controls security perimeter to perform data exploration and preprocessing.
D. Use Google-managed encryption keys to encrypt the PII data at rest, and decrypt the PII data during data exploration and preprocessing.
You are building a predictive maintenance model to preemptively detect part defects in bridges. You plan to use high definition images of the bridges as model inputs. You need to explain the output of the model to the relevant stakeholders so they can take appropriate action. How should you build the model?
A. Use scikit-learn to build a tree-based model, and use SHAP values to explain the model output.
B. Use scikit-learn to build a tree-based model, and use partial dependence plots (PDP) to explain the model output.
C. Use TensorFlow to create a deep learning-based model, and use Integrated Gradients to explain the model output.
D. Use TensorFlow to create a deep learning-based model, and use the sampled Shapley method to explain the model output.
You need to use TensorFlow to train an image classification model. Your dataset is located in a Cloud Storage directory and contains millions of labeled images. Before training the model, you need to prepare the data. You want the data preprocessing and model training workflow to be as efficient, scalable, and low maintenance as possible. What should you do?
A. 1. Create a Dataflow job that creates sharded TFRecord files in a Cloud Storage directory.
2.
Reference tf.data.TFRecordDataset in the training script.
3.
Train the model by using Vertex AI Training with a V100 GPU.
B. 1. Create a Dataflow job that moves the images into multiple Cloud Storage directories, where each directory is named according to the corresponding label
2.
Reference tfds.folder_dataset:ImageFolder in the training script.
3.
Train the model by using Vertex AI Training with a V100 GPU.
C. 1. Create a Jupyter notebook that uses an nt-standard-64 V100 GPU Vertex AI Workbench instance.
2.
Write a Python script that creates sharded TFRecord files in a directory inside the instance.
3.
Reference tf.data.TFRecordDataset in the training script.
4.
Train the model by using the Workbench instance.
D. 1. Create a Jupyter notebook that uses an n1-standard-64, V100 GPU Vertex AI Workbench instance.
2.
Write a Python script that copies the images into multiple Cloud Storage directories, where each. directory is named according to the corresponding label.
3.
Reference tfds.foladr_dataset.ImageFolder in the training script.
4.
Train the model by using the Workbench instance.
You work at a large organization that recently decided to move their ML and data workloads to Google Cloud. The data engineering team has exported the structured data to a Cloud Storage bucket in Avro format. You need to propose a workflow that performs analytics, creates features, and hosts the features that your ML models use for online prediction How should you configure the pipeline?
A. Ingest the Avro files into Cloud Spanner to perform analytics Use a Dataflow pipeline to create the features and store them in BigQuery for online prediction.
B. Ingest the Avro files into BigQuery to perform analytics Use a Dataflow pipeline to create the features, and store them in Vertex Al Feature Store for online prediction.
C. Ingest the Avro files into BigQuery to perform analytics Use BigQuery SQL to create features and store them in a separate BigQuery table for online prediction.
D. Ingest the Avro files into Cloud Spanner to perform analytics. Use a Dataflow pipeline to create the features. and store them in Vertex Al Feature Store for online prediction.
What Makes leads4pass.com Differ From Others?
There are tens of thousands of certification exam dumps provided on the internet. To keep the exam dumps valid, the exam questions latest and the exam answers accurate should be the first aim. Also, to make the exam PDF and exam VCE simulator easy to use is very important. Besides, leads4pass.com has 100% pass guarantee policy. Free exam demo is available. Customer support team is ready to help at any time when required.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
All rights are reserved by leads4pass.com. Any changes, copy or trademarks abuse will be regarded as infringement. leads4pass.com will reserve the right to pursue accountability.
Copyright © 2004-2025 leads4pass.com.