E20-026 Online Practice Questions and Answers
Under which circumstance do you need to implement N-fold cross-validation after creating a regression model?
A. There is not enough data to create a test set.
B. The data is unformatted.
C. There are missing values in the data.
D. There are categorical variables in the model.
In which lifecycle stage are initial hypotheses formed?
A. Discovery
B. Model planning
C. Model building
D. Data preparation
You have been assigned to do a study of the daily revenue effect of a pricing model of online transactions. All the data currently available to you has been loaded into your analytics database; revenue data, pricing data, and online transaction data. You find that all the data comes in different levels of granularity. The transaction data has timestamps (day, hour, minutes, seconds), pricing is stored at the daily level, and revenue data is only reported monthly. What is your next step?
A. Report back to the business owner that the current data model does not support the business question.
B. Interpolate a daily model for revenue from the monthly revenue data.
C. Aggregate all data to the monthly level in order to create a monthly revenue model.
D. Disregard revenue as a driver in the pricing model,and create a daily model based on pricing and transactions only.
You are attempting to find the Euclidean distance between two centroids:
Centroid A's coordinates: (X = 2, Y = 4)
Centroid B's coordinates (X = 8, Y = 10)
Which formula finds the correct Euclidean distance?
A. SQRT((2-8)2+(4-10)2) or 8.49
B. SQRT(((2-8) x 2) + ((4-10) x 2)) or 12.17
C. ((2-8)2+(4-10)2) or 72
D. ((2-8) x 2 + (4-10) x 2) or 148
Refer to the exhibit.
You have run a linear regression model against your data, and have plotted true outcome versus predicted
outcome. The R-squared of your model is 0.75. What is your assessment of the model?
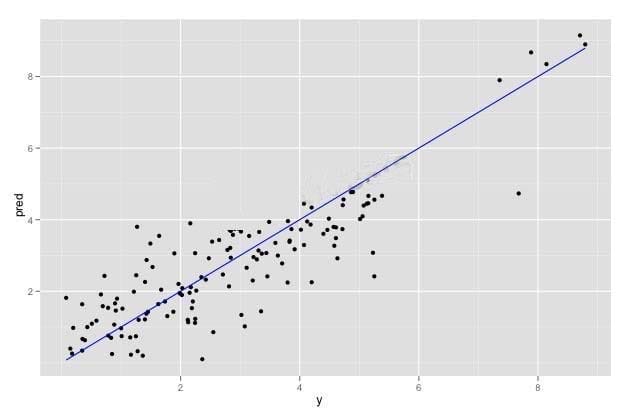
A. The R-squared may be biased upwards by the extreme-valued outcomes. Remove them and refit to get a better idea of the model's quality over typical data.
B. The R-squared is good. The model should perform well.
C. The extreme-valued outliers may negatively affect the model's performance. Remove them to see if the R-squared improves over typical data.
D. The observations seem to come from two different populations,but this model fits them both equally well.
Refer to the exhibit.
You are using k-means clustering to discover groupings within a data set. You plot within-sum-of-squares
(wss) of multiple cluster sizes. Based on the exhibit, how many clusters should you use in your analysis?
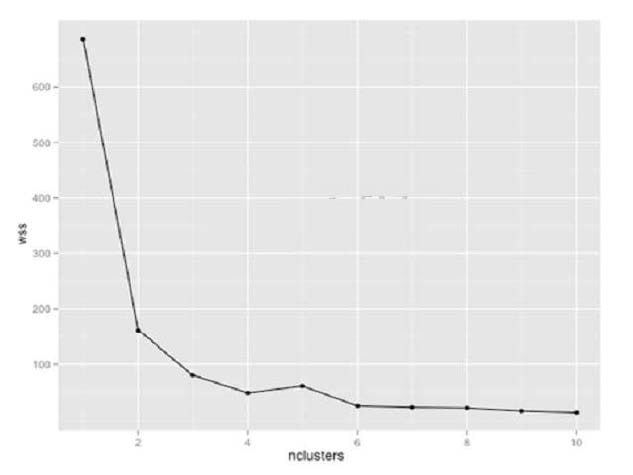
A. 4
B. 2
C. 8
D. 10
Refer to the exhibit.
In the exhibit, a correlogram is provided based on an autocorrelation analysis of a sample dataset.
What can you conclude from only this exhibit?
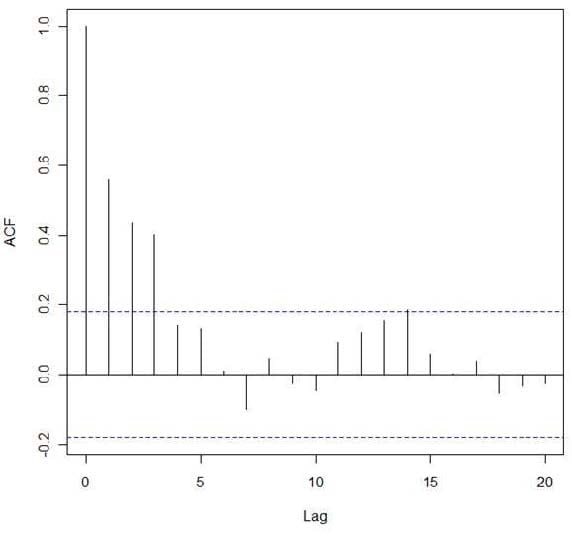
A. There is significant autocorrelation through lag 3
B. There is no structure left to model in the data
C. Lag 7 has a significant negative autocorrelation
D. Differencing is required before proceeding with any analysis
Refer to the exhibit.
You ran a linear regression, and the final output is seen in the exhibit. Based only on the information in the
exhibit and an acceptable confidence level of 95%, how would you interpret the interaction of variable D
with the dependent variable?
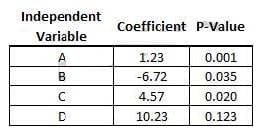
A. In this model,Variable D is not significantly interacting with the dependent variable
B. For every 1 unit increase in variable D,holding all other variables constant,we can expect the dependent variable to increase by 10.23 units
C. For every 1 unit increase in variable D,holding all other variables constant,we can expect the dependent variable to be multiplied by 10.23 units
D. Variable D is more significant than variables A,B,and C.
Refer to the exhibit Consider the training data set shown in the exhibit. What are the classification (Y = 0 or 1) and the probability of the classification for the tuple X(1, 0, 0) using Naive Bayesian classifier?
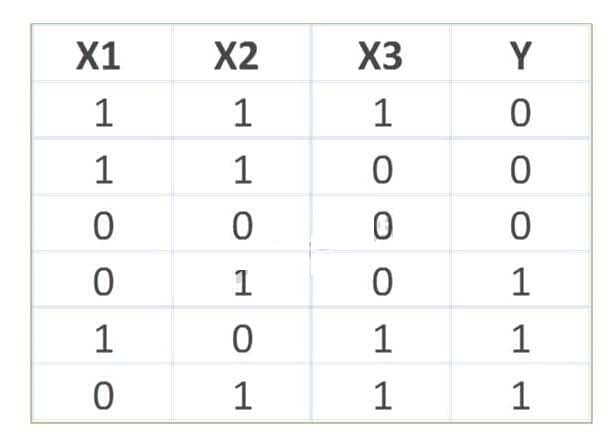
A. Classification Y = 0,Probability = 4/54
B. Classification Y = 1,Probability = 4/54
C. Classification Y = 0,Probability = 1/54
D. Classification Y = 1,Probability = 1/54
Which ROC curve represents a perfect model fit? A)
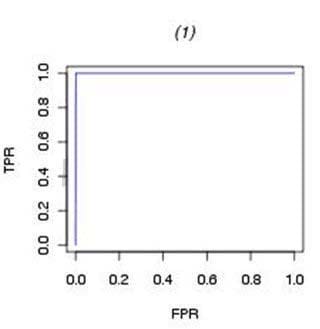
B)
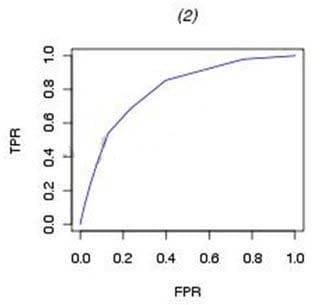
C) 52 / 55
D)
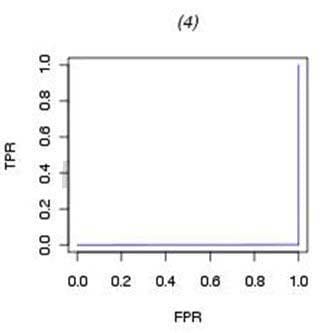
A. Exhibit A
B. Exhibit B
C. Exhibit C
D. Exhibit D
What Makes leads4pass.com Differ From Others?
There are tens of thousands of certification exam dumps provided on the internet. To keep the exam dumps valid, the exam questions latest and the exam answers accurate should be the first aim. Also, to make the exam PDF and exam VCE simulator easy to use is very important. Besides, leads4pass.com has 100% pass guarantee policy. Free exam demo is available. Customer support team is ready to help at any time when required.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
All rights are reserved by leads4pass.com. Any changes, copy or trademarks abuse will be regarded as infringement. leads4pass.com will reserve the right to pursue accountability.
Copyright © 2004-2025 leads4pass.com.