DP-203 Online Practice Questions and Answers
DRAG DROP
You have an Azure subscription.
You plan to build a data warehouse in an Azure Synapse Analytics dedicated SQL pool named pool1 that will contain staging tables and a dimensional model. Pool1 will contain the following tables.
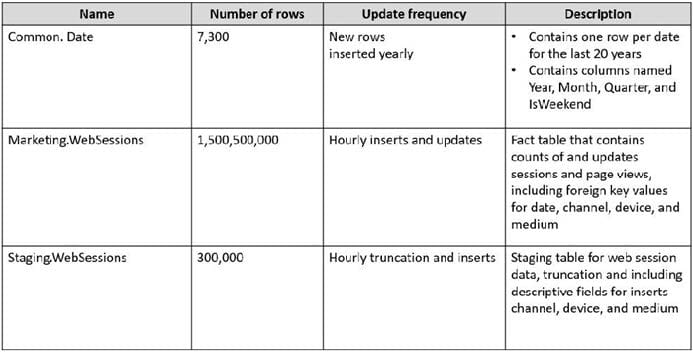
You need to design the table storage for pool1. The solution must meet the following requirements:
Maximize the performance of data loading operations to Staging.WebSessions. Minimize query times for reporting queries against the dimensional model.
Which type of table distribution should you use for each table? To answer, drag the appropriate table distribution types to the correct tables. Each table distribution type may be used once, more than once, or not at all. You may need to drag
the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:


HOTSPOT
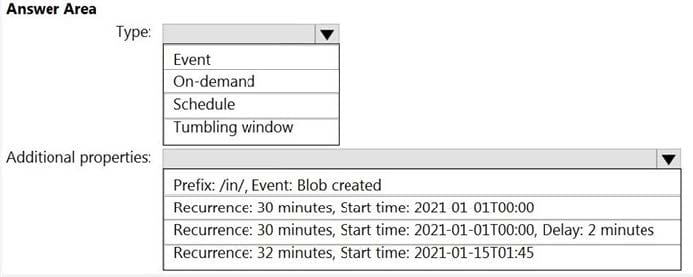
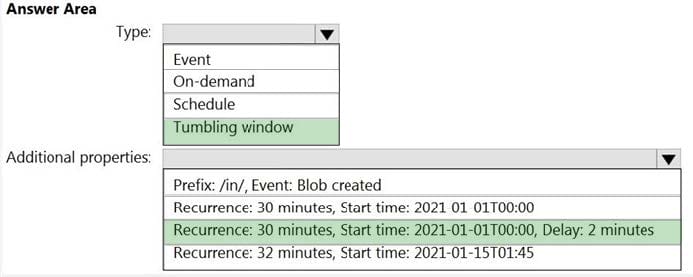
You build an Azure Data Factory pipeline to move data from an Azure Data Lake Storage Gen2 container to a database in an Azure Synapse Analytics dedicated SQL pool.
Data in the container is stored in the following folder structure.
/in/{YYYY}/{MM}/{DD}/{HH}/{mm}
The earliest folder is /in/2021/01/01/00/00. The latest folder is /in/2021/01/15/01/45.
You need to configure a pipeline trigger to meet the following requirements:
Existing data must be loaded.
Data must be loaded every 30 minutes.
Late-arriving data of up to two minutes must he included in the load for the time at which the data should have arrived.
How should you configure the pipeline trigger? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
You plan to create an Azure Synapse Analytics dedicated SQL pool.
You need to minimize the time it takes to identify queries that return confidential information as defined by the company's data privacy regulations and the users who executed the queues.
Which two components should you include in the solution? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. sensitivity-classification labels applied to columns that contain confidential information
B. resource tags for databases that contain confidential information
C. audit logs sent to a Log Analytics workspace
D. dynamic data masking for columns that contain confidential information

You are designing a sales transactions table in an Azure Synapse Analytics dedicated SQL pool. The table will contains approximately 60 million rows per month and will be partitioned by month. The table will use a clustered column store index and round-robin distribution.
Approximately how many rows will there be for each combination of distribution and partition?
A. 1 million
B. 5 million
C. 20 million
D. 60 million
You build a data warehouse in an Azure Synapse Analytics dedicated SQL pool.
Analysts write a complex SELECT query that contains multiple JOIN and CASE statements to transform data for use in inventory reports. The inventory reports will use the data and additional WHERE parameters depending on the report. The
reports will be produced once daily.
You need to implement a solution to make the dataset available for the reports. The solution must minimize query times.
What should you implement?
A. an ordered clustered columnstore index
B. a materialized view
C. result set caching
D. a replicated table
You have an Azure Data Factory pipeline that performs an incremental load of source data to an Azure Data Lake Storage Gen2 account.
Data to be loaded is identified by a column named LastUpdatedDate in the source table.
You plan to execute the pipeline every four hours.
You need to ensure that the pipeline execution meets the following requirements:
1.
Automatically retries the execution when the pipeline run fails due to concurrency or throttling limits.
2.
Supports backfilling existing data in the table. Which type of trigger should you use?
A. event
B. on-demand
C. on-demand
D. tumbling window
You are designing a folder structure for the files m an Azure Data Lake Storage Gen2 account. The account has one container that contains three years of data. You need to recommend a folder structure that meets the following requirements:
1.
Supports partition elimination for queries by Azure Synapse Analytics serverless SQL pooh
2.
Supports fast data retrieval for data from the current month
3.
Simplifies data security management by department Which folder structure should you recommend?
A. \Department\DataSource\YYYY\MM\DataFile_YYYYMMDD.parquet
B. \DataSource\Department\YYYYMM\DataFile_YYYYMMDD.parquet
C. \DD\MM\YYYY\Department\DataSource\DataFile_DDMMYY.parquet
D. \YYYY\MM\DD\Department\DataSource\DataFile_YYYYMMDD.parquet
You have an Azure Data Lake Storage Gen2 account that contains two folders named Folder and Folder2.
You use Azure Data Factory to copy multiple files from Folder1 to Folder2.
You receive the following error.
Operation on target Copy_sks failed: Failure happened on 'Sink' side.
ErrorCode=DelimitedTextMoreColumnsThanDefined,
'Type=Microsoft.DataTransfer.Common.Snared.HybridDeliveryException,
Message=Error found when processing 'Csv/Tsv Format Text' source
'0_2020_11_09_11_43_32.avro' with row number 53: found more columns than expected column count 27., Source=Microsoft.DataTransfer.Comnon,'
What should you do to resolve the error?
A. Add an explicit mapping.
B. Enable fault tolerance to skip incompatible rows.
C. Lower the degree of copy parallelism
D. Change the Copy activity setting to Binary Copy
You have an Azure Data Factory pipeline named Pipeline1!. Pipelinel contains a copy activity that sends data to an Azure Data Lake Storage Gen2 account. Pipeline 1 is executed by a schedule trigger.
You change the copy activity sink to a new storage account and merge the changes into the collaboration branch.
After Pipelinel executes, you discover that data is NOT copied to the new storage account.
You need to ensure that the data is copied to the new storage account.
What should you do?
A. Publish from the collaboration branch.
B. Configure the change feed of the new storage account.
C. Create a pull request.
D. Modify the schedule trigger.
You have an Azure Synapse Analytics dedicated SQL pool.
You plan to create a fact table named Table1 that will contain a clustered columnstore index.
You need to optimize data compression and query performance for Table1.
What is the minimum number of rows that Table1 should contain before you create partitions?
A. 100,000
B. 600,000
C. 1 million
D. 60 million
What Makes leads4pass.com Differ From Others?
There are tens of thousands of certification exam dumps provided on the internet. To keep the exam dumps valid, the exam questions latest and the exam answers accurate should be the first aim. Also, to make the exam PDF and exam VCE simulator easy to use is very important. Besides, leads4pass.com has 100% pass guarantee policy. Free exam demo is available. Customer support team is ready to help at any time when required.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
All rights are reserved by leads4pass.com. Any changes, copy or trademarks abuse will be regarded as infringement. leads4pass.com will reserve the right to pursue accountability.
Copyright © 2004-2025 leads4pass.com.