DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST Online Practice Questions and Answers
You are working on a problem where you have to predict whether the claim is done valid or not. And you find that most of the claims which are having spelling errors as well as corrections in the manually filled claim forms compare to the honest claims. Which of the following technique is suitable to find out whether the claim is valid or not?
A. Naive Bayes
B. Logistic Regression
C. Random Decision Forests
D. Any one of the above
Suppose you have been given a relatively high-dimension set of independent variables and you are asked to come up with a model that predicts one of Two possible outcomes like "YES" or "NO", then which of the following technique best fit?
A. Support vector machines
B. Naive Bayes
C. Logistic regression
D. Random decision forests
E. All of the above
Refer to exhibit
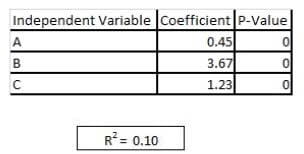
You are asked to write a report on how specific variables impact your client's sales using a data set provided to you by the client. The data includes 15 variables that the client views as directly related to sales, and you are restricted to these variables only. After a preliminary analysis of the data, the following findings were made: 1. Multicollinearity is not an issue among the variables 2. Only three variables-A, B, and C-have significant correlation with sales You build a linear regression model on the dependent variable of sales with the independent variables of A, B, and C. The results of the regression are seen in the exhibit. You cannot request additional data. what is a way that you could try to increase the R2 of the model without artificially inflating it?
A. Create clusters based on the data and use them as model inputs
B. Force all 15 variables into the model as independent variables
C. Create interaction variables based only on variables A, B, and C
D. Break variables A, B, and C into their own univariate models
Which of the following metrics are useful in measuring the accuracy and quality of a recommender system?
A. Cluster Density
B. Support Vector Count
C. Mean Absolute Error
D. Sum of Absolute Errors
You are doing advanced analytics for the one of the medical application using the regression and you have two variables which are weight and height and they are very important input variables, which cannot be ignored and they are also
highly co-related.
What is the best solution for that?
A. You will take cube root of height
B. You will take square root of weight
C. You will take square of the height.
D. You would consider using BMI (Body Mass Index)
What describes a true limitation of Logistic Regression method?
A. It does not handle redundant variables well.
B. It does not handle missing values well.
C. It does not handle correlated variables well.
D. It does not have explanatory values.
Select the correct statement which applies to Supervised learning
A. We asks the machine to learn from our data when we specify a target variable.
B. Lesser machine's task to only divining some pattern from the input data to get the target variable
C. Instead of telling the machine Predict Y for our data X, we're asking What can you tell me about X?
A problem statement is given as below
Hospital records show that of patients suffering from a certain disease, 75% die of it. What is the probability that of 6 randomly selected patients, 4 will recover?
Which of the following model will you use to solve it.
A. Binomial
B. Poisson
C. Normal
D. Any of the above
What type of output generated in case of linear regression?
A. Continuous variable
B. Discrete Variable
C. Any of the Continuous and Discrete variable
D. Values between 0 and 1
You are having 1000 patients' data with the height and age. Where age in years and height in meters. You wanted to create cluster using this two attributes. You wanted to have near equal effect for both the age and height while creating the cluster. What you can do?
A. You will be adding height with the numeric value 100
B. You will be converting each height value to centimeters
C. You will be dividing both age and height with their respective standard deviation
D. You will be taking square root of height
What Makes leads4pass.com Differ From Others?
There are tens of thousands of certification exam dumps provided on the internet. To keep the exam dumps valid, the exam questions latest and the exam answers accurate should be the first aim. Also, to make the exam PDF and exam VCE simulator easy to use is very important. Besides, leads4pass.com has 100% pass guarantee policy. Free exam demo is available. Customer support team is ready to help at any time when required.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
All rights are reserved by leads4pass.com. Any changes, copy or trademarks abuse will be regarded as infringement. leads4pass.com will reserve the right to pursue accountability.
Copyright © 2004-2024 leads4pass.com.