CKA Online Practice Questions and Answers
SIMULATION
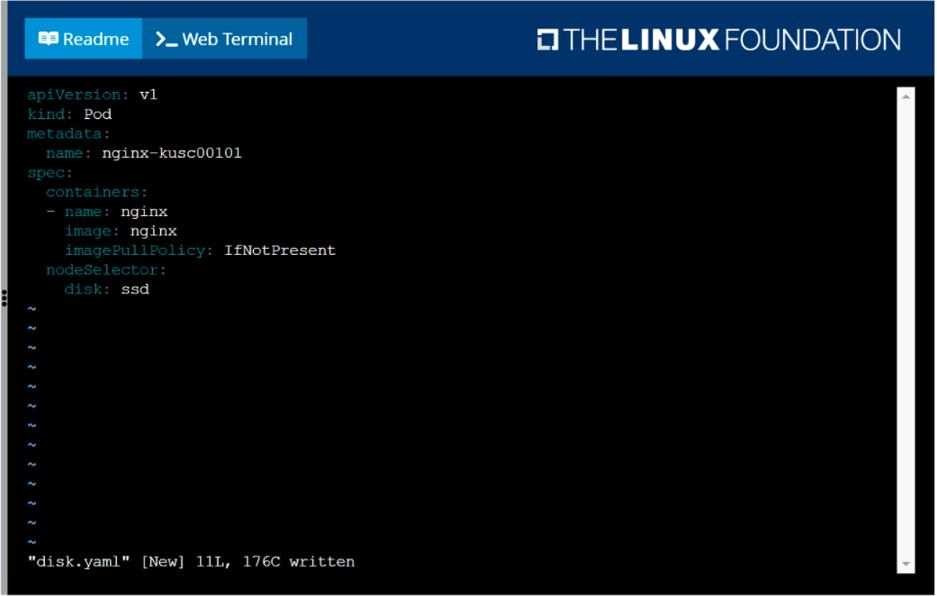
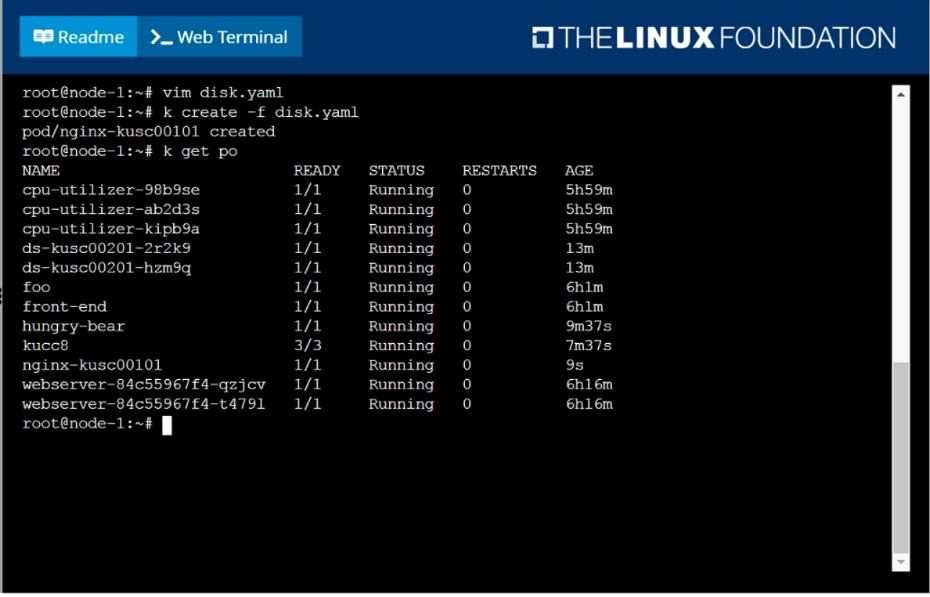
Schedule a pod as follows:
1.
Name: nginx-kusc00101
2.
Image: nginx
3.
Node selector: disk=ssd
SIMULATION
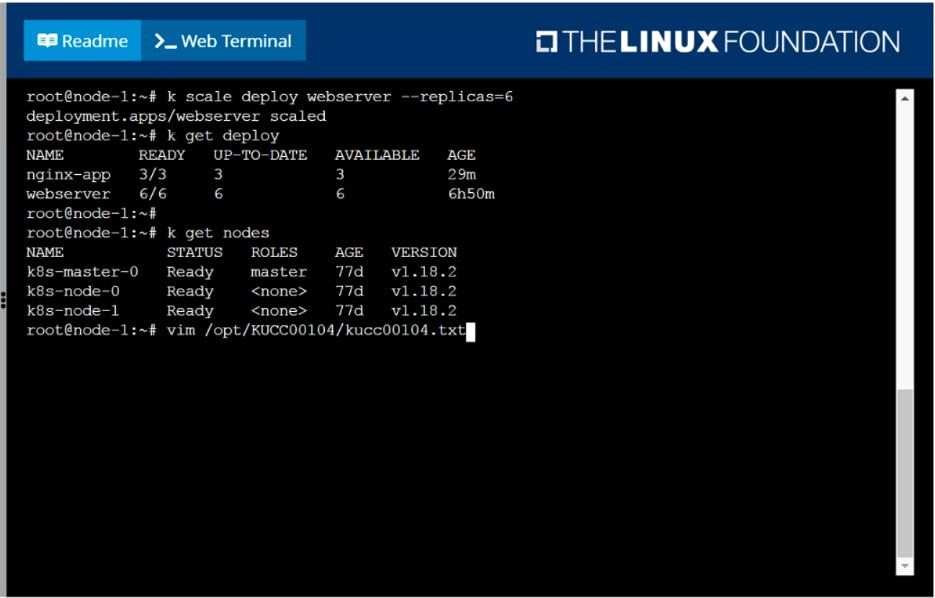
Check to see how many worker nodes are ready (not including nodes tainted NoSchedule) and write the number to /opt/KUCC00104/kucc00104.txt.
SIMULATION
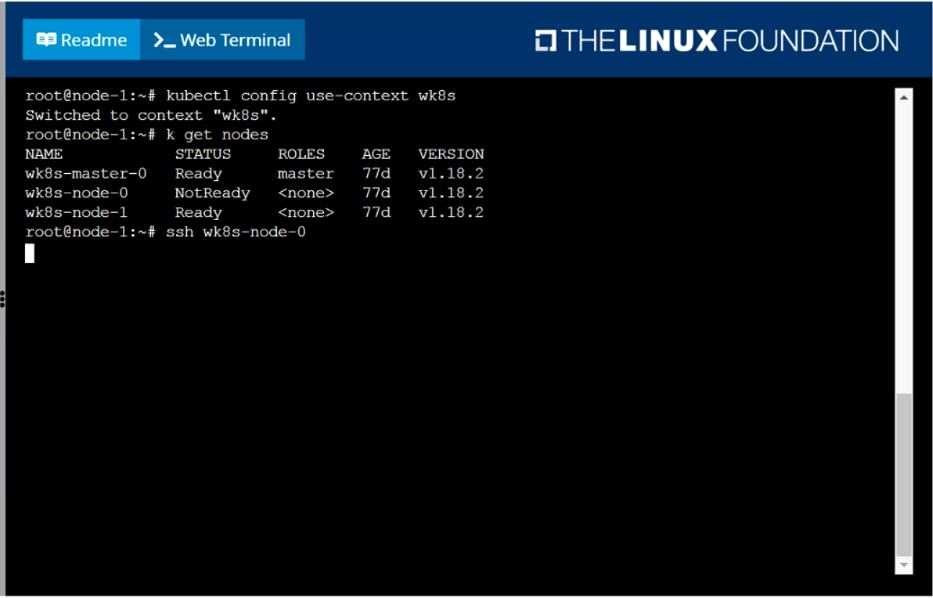
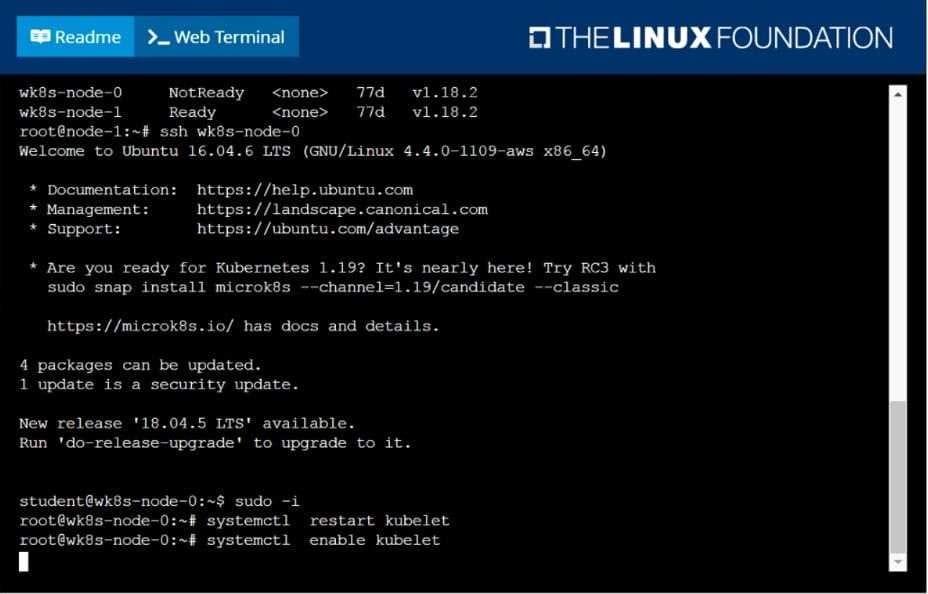
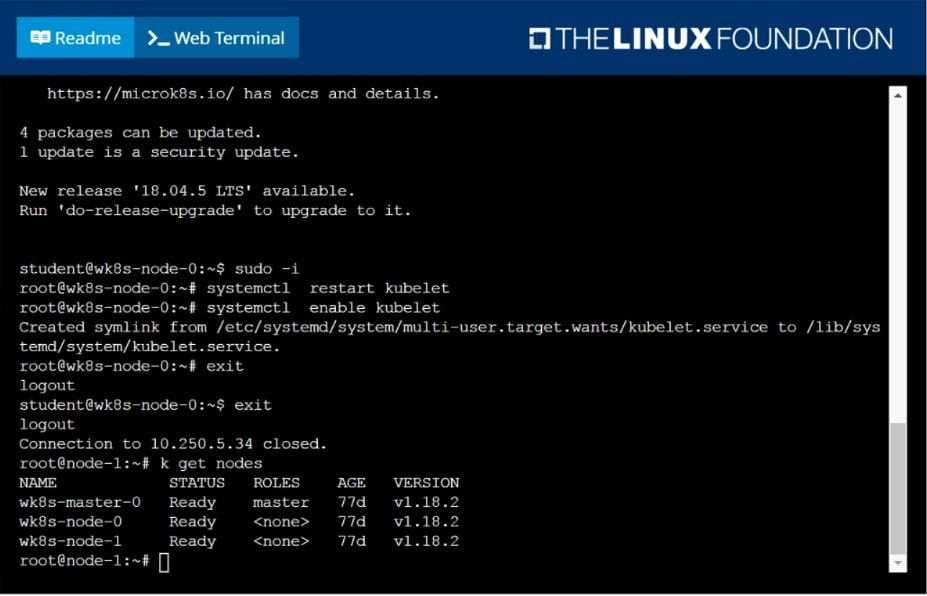
A Kubernetes worker node, named wk8s-node-0 is in state NotReady. Investigate why this is the case, and perform any appropriate steps to bring the node to a Ready state, ensuring that any changes are made permanent.
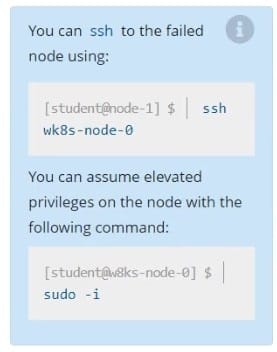
You can ssh to the failed node using:
[student@node-1] $ | ssh Wk8s-node-0
You can assume elevated privileges on the node with the following command:
[student@w8ks-node-0] $ | sudo -i
Create a pod that echo "hello world" and then exists. Have the pod deleted automatically when it's completed
SIMULATION
Task
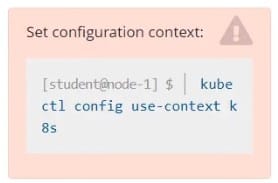
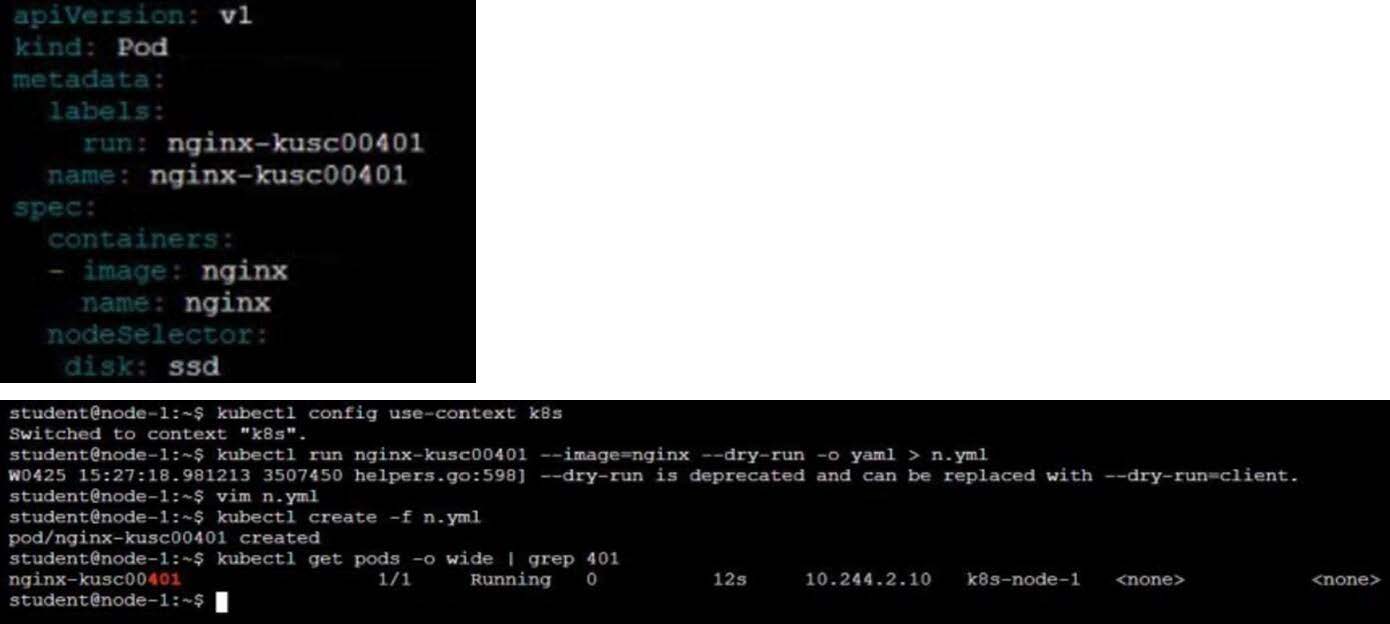
Schedule a pod as follows:
1.
Name: nginx-kusc00401
2.
Image: nginx
3.
Node selector: disk=ssd
SIMULATION
Task
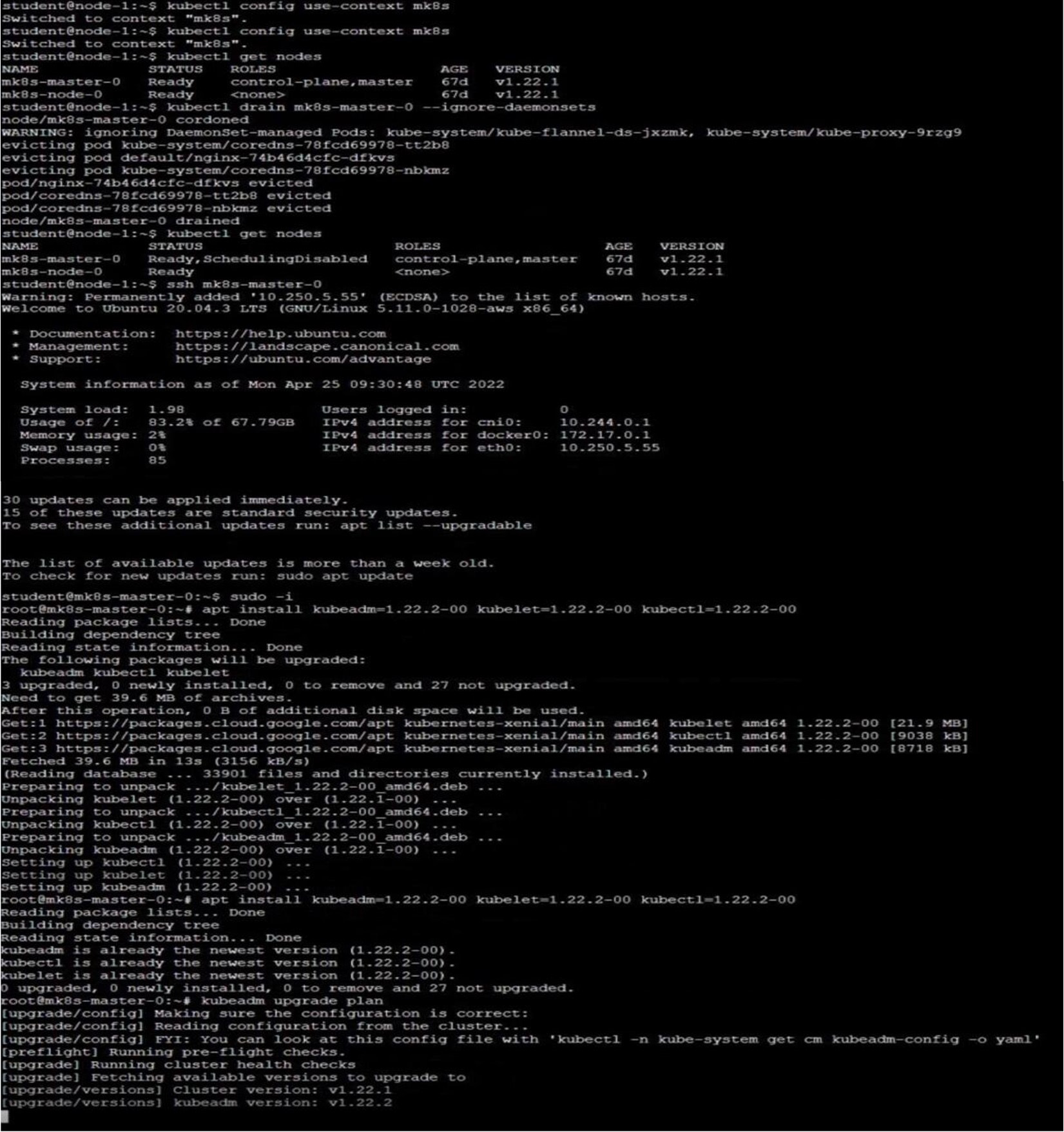
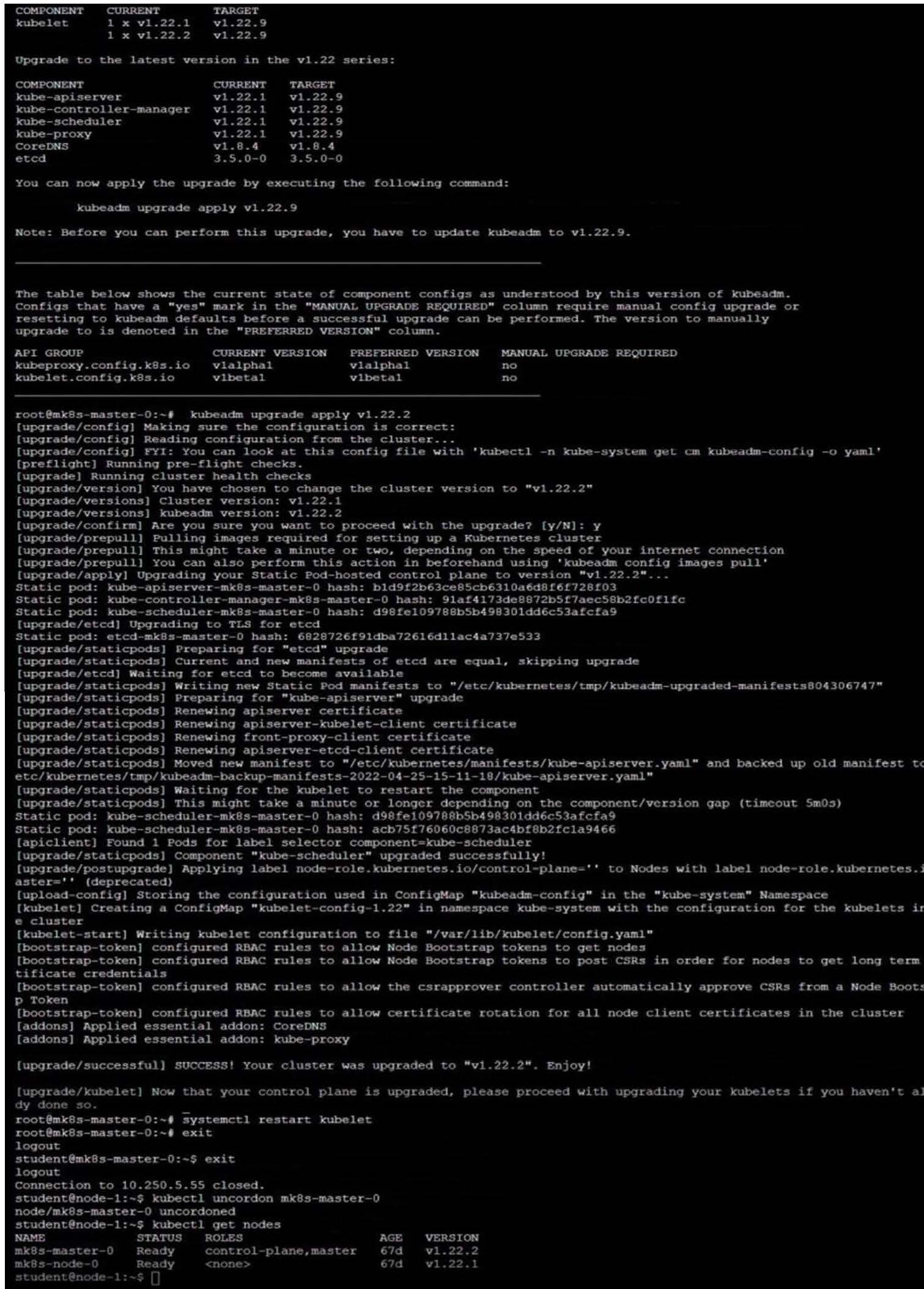
Given an existing Kubernetes cluster running version 1.20.0, upgrade all of the Kubernetes control plane and node components on the master node only to version 1.20.1.
Be sure to drain the master node before upgrading it and uncordon it after the upgrade.
You are also expected to upgrade kubelet and kubectl on the master node.

What Makes leads4pass.com Differ From Others?
There are tens of thousands of certification exam dumps provided on the internet. To keep the exam dumps valid, the exam questions latest and the exam answers accurate should be the first aim. Also, to make the exam PDF and exam VCE simulator easy to use is very important. Besides, leads4pass.com has 100% pass guarantee policy. Free exam demo is available. Customer support team is ready to help at any time when required.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
All rights are reserved by leads4pass.com. Any changes, copy or trademarks abuse will be regarded as infringement. leads4pass.com will reserve the right to pursue accountability.
Copyright © 2004-2025 leads4pass.com.