C1000-059 Online Practice Questions and Answers
Which statement is true in the context of evaluating metrics for machine learning algorithms?
A. A random classifier has AUC (the area under ROC curve) of 0.5
B. Using only one evaluation metric is sufficient
C. The F-score is always equal to precision
D. Recall of 1 (100%) is always a good result
The formula for recall is given by (True Positives) / (True Positives + False Negatives).
What is the recall for this example?

A. 0.2
B. 0.25
C. 0.5
D. 0.33
After importing a Jupyter notebook and CSV data file into IBM Watson Studio in the IBM Public Cloud project, it is discovered that the notebook code can no longer access the CSV file. What is the most likely reason for this problem?
A. CSV files cannot be used as data sources in Watson Studio.
B. The CSV file was converted to a binary blob and must be converted in the notebook code.
C. The CSV file is stored in a Cloud Object Storage.
D. The CSV file is stored in a Watson Machine Learning instance and is only accessible via REST API.
A neural network is trained for a classification task. During training, you monitor the loss function for the train dataset and the validation dataset, along with the accuracy for the validation dataset. The goal is to get an accuracy of 95%.
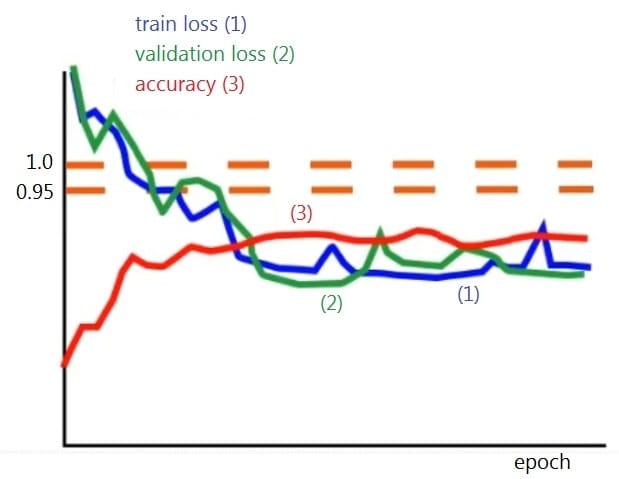
From the graph, what modification would be appropriate to improve the performance of the model?
A. increase the depth of the neural network
B. insert a dropout layer in the neural network architecture
C. increase the proportion of the train dataset by moving examples from the validation dataset to the train dataset
D. restart the training with a higher learning rate
When communicating technical results to business stakeholders, what are three appropriate topics to include? (Choose three.)
A. methods that failed
B. newest developments in AI methods
C. benefits of cognitive over business analytics
D. realistic impact on the business measures
E. differences between cloud provider portfolios
F. alternative methods to address the business problem
What is meant by part-of-speech tagging in the context of text analytics?
A. replaces words with synonyms, e g. answer for reply
B. translates word by word
C. finds the root word
D. determines the category of a word, e.g nouns
What is a class of machine learning problems where the algorithm builds a mathematical model from a set of data that contains both the inputs and the desired outputs?
A. unsupervised learning
B. mentoring
C. reinforcement learning
D. supervised learning
What is the main difference between traditional programming and machine learning?
A. Machine learning models take less time to train.
B. Machine learning takes full advantage of SDKs and APIs.
C. Machine learning is optimized to run on parallel computing and cloud computing.
D. Machine learning does not require explicit coding of decision logic.
A data analyst creates a term-document matrix for the following sentence:
I saw a cat, a dog and another cat.
Assuming they used a binary vectorizer, what is the resulting weight for the word cat?
A. 0
B. 1
C. 3
D. 2
Given the following sentence:
The dog jumps over a fence.
What would a vectorized version after common English stopword removal look like?
A. ['dog', 'fence', 'run']
B. ['fence', 'jumps']
C. ['dog', 'fence', 'jumps']
D. ['a', 'dog', 'fence', 'jumps', 'over', 'the']
What Makes leads4pass.com Differ From Others?
There are tens of thousands of certification exam dumps provided on the internet. To keep the exam dumps valid, the exam questions latest and the exam answers accurate should be the first aim. Also, to make the exam PDF and exam VCE simulator easy to use is very important. Besides, leads4pass.com has 100% pass guarantee policy. Free exam demo is available. Customer support team is ready to help at any time when required.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
All rights are reserved by leads4pass.com. Any changes, copy or trademarks abuse will be regarded as infringement. leads4pass.com will reserve the right to pursue accountability.
Copyright © 2004-2025 leads4pass.com.